
Sketch and Streaming Algorithm
Challenge in Big Data
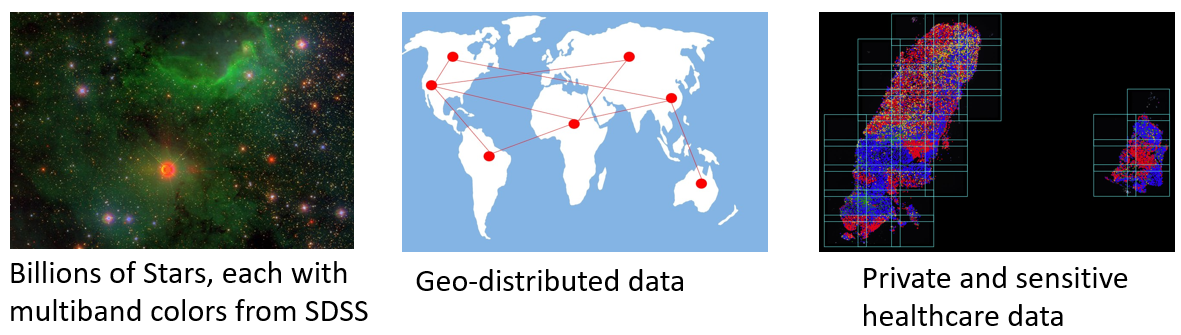
Nowadays, data sets with very large cardinalities are emerging. They may have strong clustering with high density contrasts. Finding those clusters in low dimension is a practical challenge because existing embedding tools scale poorly. They break down after 100K points. The typical runtime of data with size n is in the order of n squared. Even recent improvements to $O(n \log n)$, along with new parallel techniques, cannot handle data in millions, let alone in billions or trillions. More importantly, Data today are often geo-distributed. It’s impossible to aggregate directly since all data must reside on the same server for that. Meanwhile, due to policies and regulations, free movement of data especially private data like healthcare is also challenging.
PCA, tSNE and UMAP
High-dimensional data is not easy to work with. Reducing the dimension by projecting or embedding is the only way to understand its structure. Among all existing embedding techniques, tSNE and UMAP are probably the most popular ones. As non-linear embeddings, they use local relationships between points to create a low-dimensional mapping. which renders better results than linear ones like PCA. 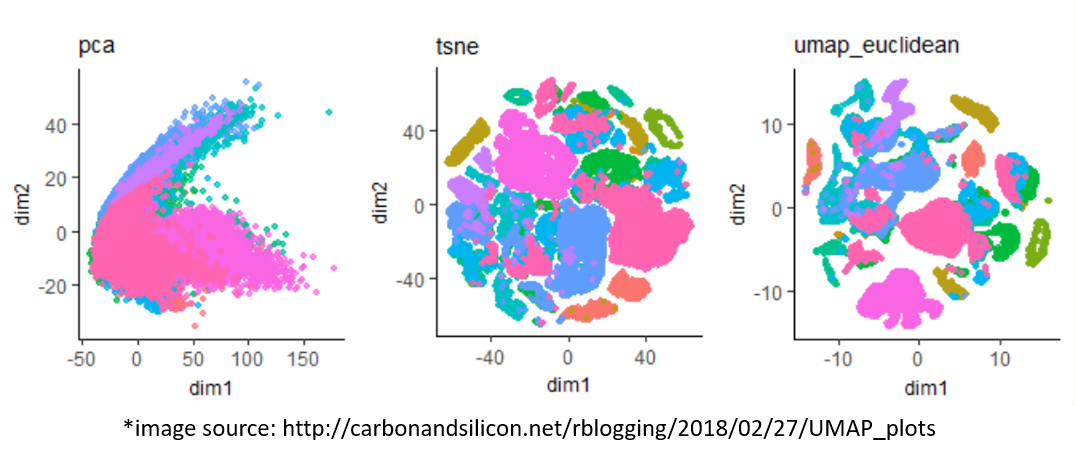
Problem with tSNE and UMAP
They break down over >10k points
Our Algorithm
We build a preprocessing pipeline for vanilla tSNE or UMAP, we call it the sketch & scale pipeline. It enables linear scaling while preserving high quality embedding, which we verified on 2 real world datasets from healthcare and astrophysics domains. Moreover, it enables aggregation and low level privacy, which is paving the road to federated and geo-distributed settings.


- PCA
- Normalization/Quantization
- Encode stream
- Count Sketch
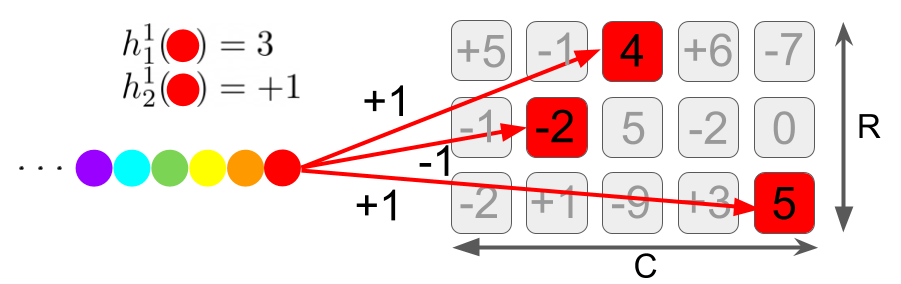
- Heavy Hitters
- tSNE & UMAP