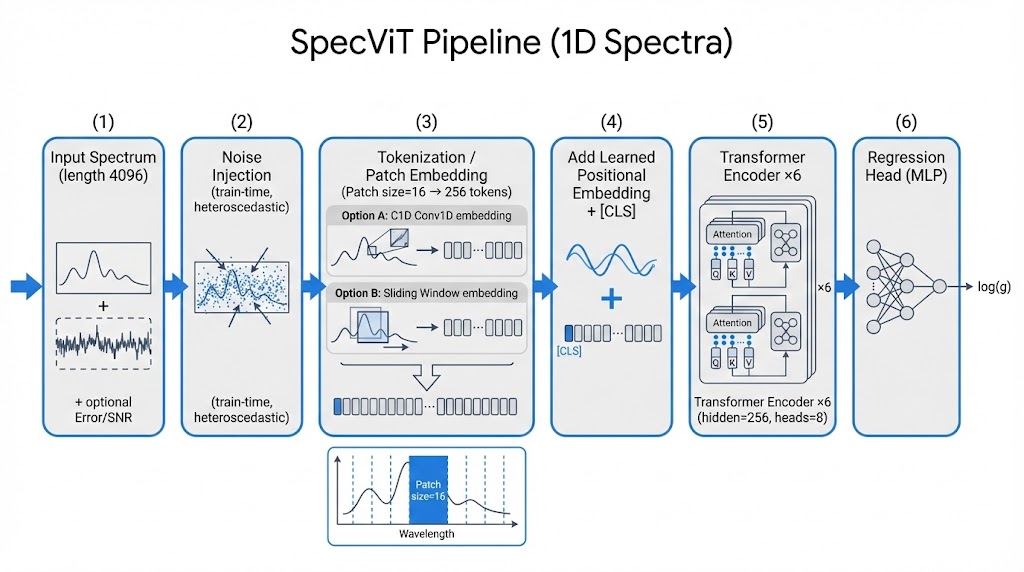
Method: Architecture Walkthrough
SpecViT applies Vision Transformer architecture to 1D stellar spectra:
Spectrum (4096 px) → 256 Patches → Token Embed → 6-Layer ViT → log g
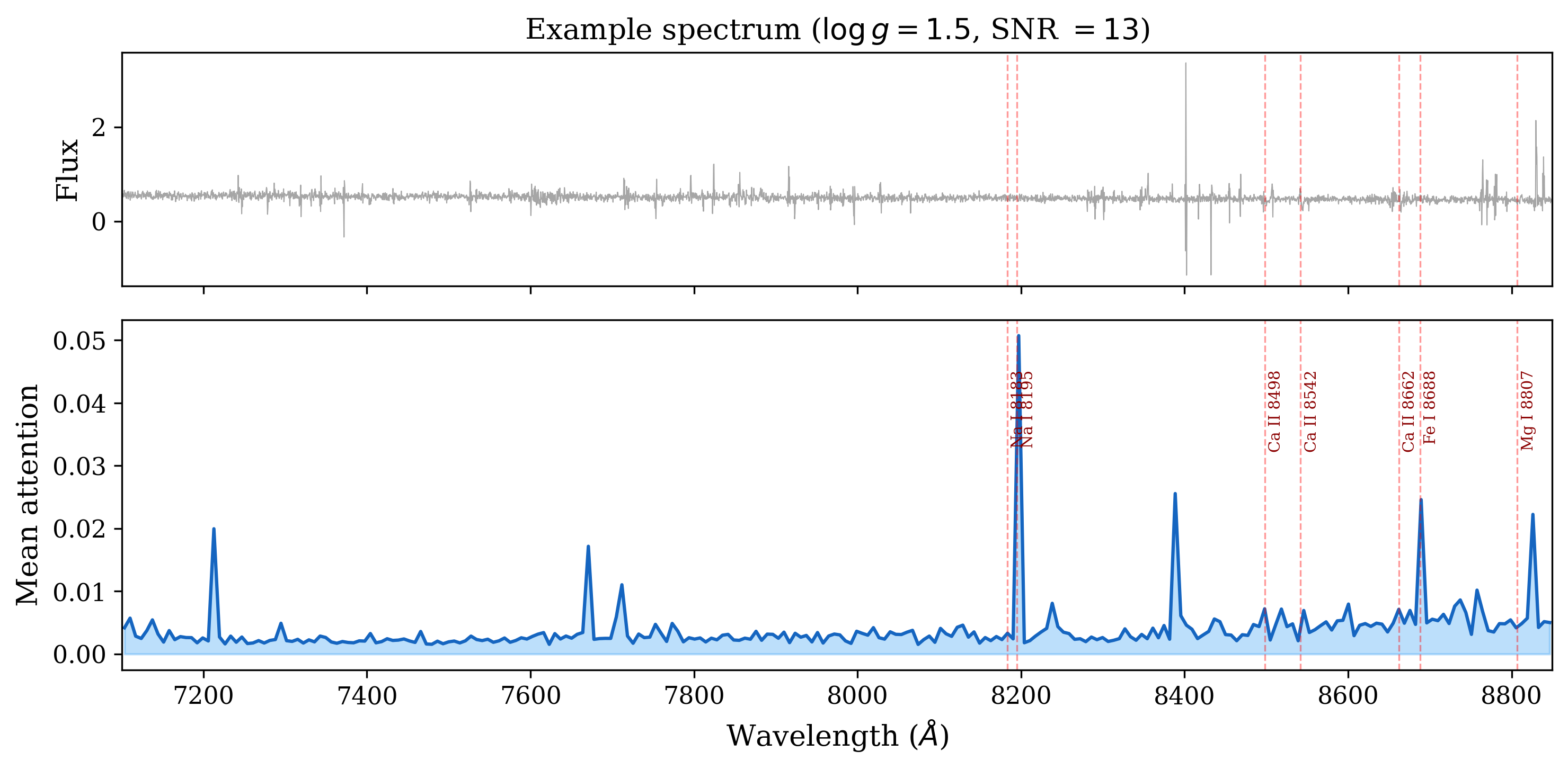
Interactive: Tokenization Visualizer
Hover over patches to see how the spectrum is divided. Patch colors show attention weight — brighter means higher attention.
Key Equations
Patch embedding:
Self-attention:
Training loss (Huber):